#ApaperADay: 30-days challenge reading one AI paper per day (week 2)
- Camilo vasquez

- 25 ago 2018
- 3 Min. de lectura
Following my experience in the 30 days of the challenge #ApaperADay from @nurture.ai. Each section contains the main insights obtained from each paper during the second week of the challenge (For the first week you can see this post). This post will be updated day by day according to the reading process.
Day 8
The authors propose a procedure to optimize hyperparameters of a deep learning model. The aim is to consider a low-dimensional representation of the original data (images with lower resolution) to identify promising areas of the hyperparameter space. Afterwards, this information can be used to initialize an optimization algorithm that find the most accurate set of hyperparameters for the deep learning model (See Figure)

The authors consider several optimization algorithms for the hyperparameter tuning, including random search, the tree of parzen estimators (TPEs), sequential model-based algorithm configuration (SMAC), and genetic algorithms (GA). The results indicate that is is possible to speed-up the optimization process by using the low-dimensional representation of the data at the beginning. In addition, the procedure shows to be also independent from the optimization algorithm.
Day 9
The authors introduced a new unit for recurrent neural networks (RNN) called Relational memory core (RMC). This unit aims to perform memory interactions in tasks that involve relational reasoning. The new model is tested in several scenarios related to reinforcement learning and language modeling, where it obtained state-of-art results , especially for large text datasets. The TensorFlow implementation of the authors approach is available in the Sonet library here: https://github.com/deepmind/sonnet/blob/master/sonnet/python/modules/relational_memory.py
Day 10
This is another very nice paper with a highly novel approach to optimize hyperparameters of deep learning models. Definitively is a work to follow.
Recent advances in reverse-mode automatic differentiation allow for optimizing hyperparameters of deep learning models with gradients. The hyperparameters of the architecture are considered as normal weight parameters to be adjusted using gradients. The proposed approach is based on automatic differentiation (AD), which has big advantages compared to traditional hyperparameter tuning methods such as Bayesian optimization (BO).
AD can tune hundreds of thousands of hyperparameters (e.g. L1 norm or dropout probability for every neuron) or dynamic (e.g. learning rates for every neuron at every iteration), compared to BO, which as a global optimization approach is not able to optimize more than 20 hyperparameters. The proposed approach shows to be one of the first research attempts to automatically tune thousands of hyperparameters of deep neural networks. The code is freely available here; however is a little bit difficult to set up and start.
https://github.com/bigaidream-projects/drmad
Day 11
Currently, generative adversarial networks (GAN) are the state-of-art method for image generation considering a great deal of possibilities. GANs can produce images of surprising complexity and realism; however the GAN structure does not consider the fact than an image is a 2D representation of a composition of multiple objects interacting in a 3D visual world. The authors of the current paper explore the composition of multiple objects to train a GAN able to generate images that combine those multiple objects in a joint distribution. For example, considering separate images from a chair and a table in the input, the output will be a combined sample with table and chair objects, which interact in a correct way to produce a realistic combined image.
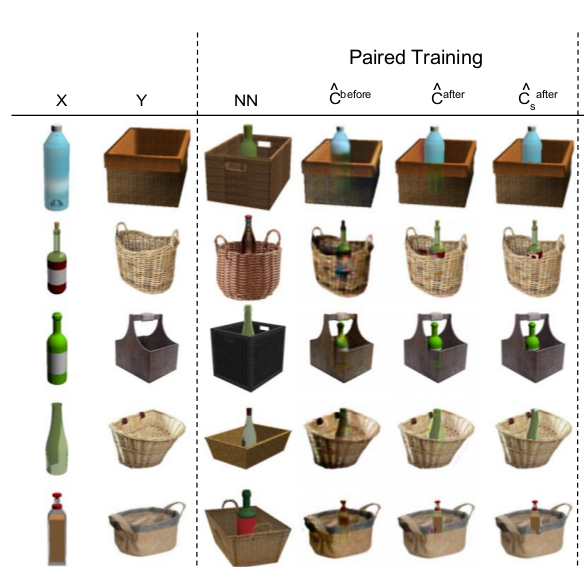
According to the authors, this is one of the first works focused on solving the compositionality problem without having any prior information about the object’s layout. This paper may open a new line of research focused on image compositionality.
Day 12
The authors propose a method to translate to a natural language the communication of multiple agents. The authors aimed to interpret message vectors from deep networks by translating them and then to learn better deep communicating policies (DCPs) between the agents. Additional material can be found in this video from the authors
In addition the implementation is freely available here: https://github.com/jacobandreas/neuralese
Day 13
The authors proposed a state-of-art method for machine translation based on an self-attention transformation that considers a representation of the relative positions to the inputs, and the distance between the sequence elements. The self-attention transformer is based on an auto-encoder structure. The encoder is formed with two layers: a self-attention and position-wise layer. On the other hand, the decoder consists of three layers: self-attention, followed by encoder-decoder attention, followed by a position-wise feed forward layer. In addition, they use residual connections around each sublayer to help propagate position information to higher layers.

Comentarios